News • Modellfehler durchschauen und beheben
KI als „Kluger Hans“: Maßstab für zuverlässigere Pathologie-Diagnostik
Eine neue Studie von BIFOLD Forschenden an der TU Berlin gemeinsam mit dem Berliner KI-Unternehmen Aignostics, der Ludwig-Maximilians-Universität (LMU) München und dem Netherlands Cancer Institute (NKI), zeigt, dass heutige KI-Modelle für die Pathologie oft schon durch die Herkunft der zu untersuchenden Gewebeprobe durch das Krankenhaus beeinflusst werden können.
Das Team entwickelte „PathoROB“, einen weltweit ersten Bewertungsmaßstab zur Messung und Verringerung dieses Problems. PathoROB wird aktuell bereits breit eingesetzt und beeinflusst so die nächste Generation von KI-Modellen für die Pathologie. Die Studie ist jetzt im Magazin Nature Communications veröffentlicht worden.
Eine starke Leistung auf einem Standard-Benchmark [reicht] nicht aus, um einem Modell im klinischen Einsatz zu vertrauen
Julius Hense
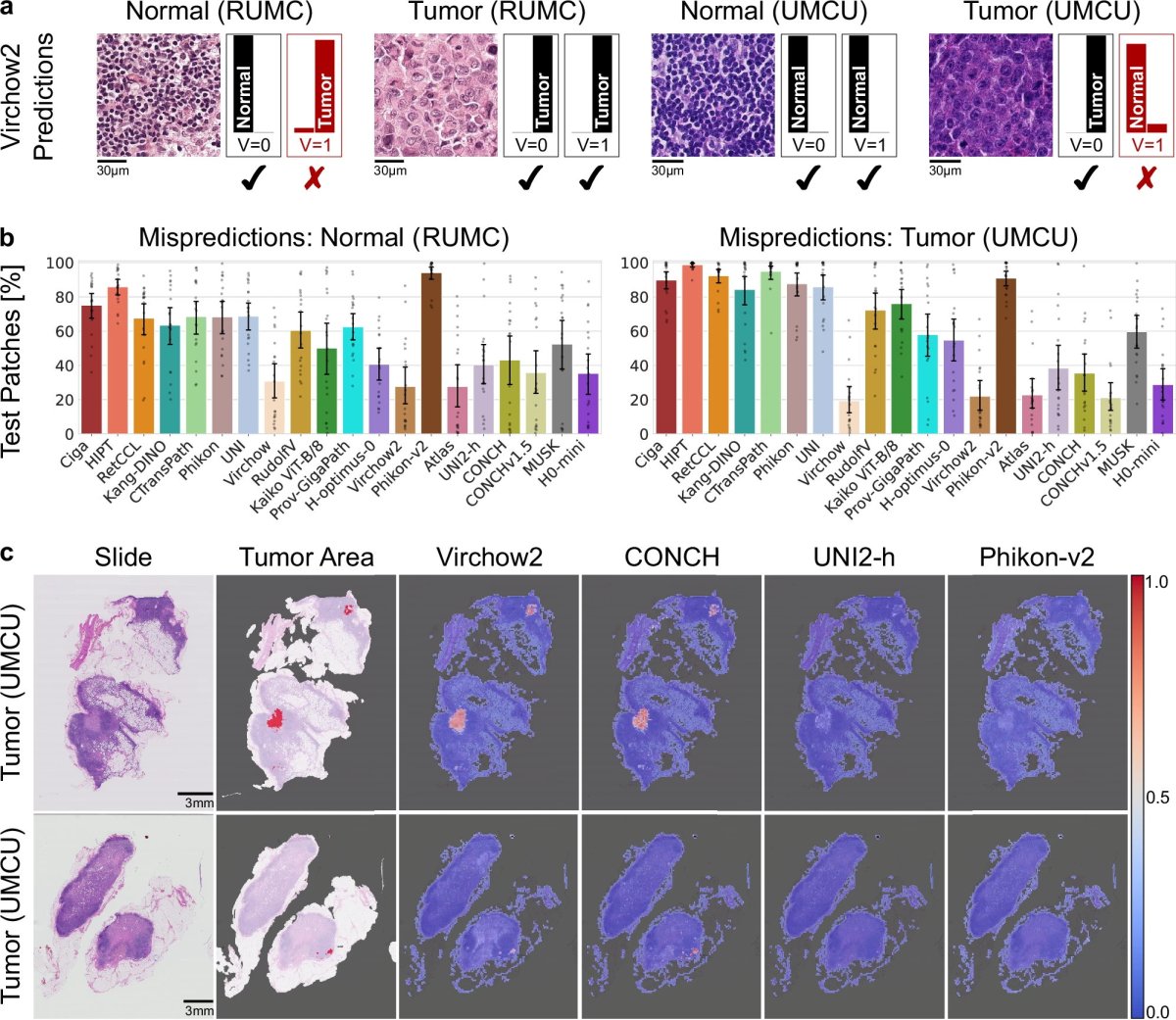
Künstliche Intelligenz soll Ärzten dabei unterstützen, Krebs schneller und präziser zu diagnostizieren und zu charakterisieren. Sogenannte Foundation Models – große KI-Systeme, die auf Millionen mikroskopischer Gewebebilder vortrainiert wurden – werden zunehmend zur Krebsdetektion, Krankheitsklassifikation und Biomarker-Vorhersage in klinischen Arbeitsabläufen eingesetzt. Die neue Studie des interdisziplinären Forschungsteams deckt nun eine kritische Schwachstelle dieser Modelle auf: Jedes Pathologielabor hinterlässt eine subtile Signatur auf seinen Gewebeschnitten: Unterschiede bei der Präparation, Färbung und Digitalisierung von Biopsien. Diese Unterschiede sind medizinisch irrelevant, für KI-Systeme jedoch sichtbar und die Modelle verinnerlichen sie. Die Forschenden zeigten, dass aktuelle Foundation Models anhand ihrer gelernten Merkmalsrepräsentationen das Herkunftskrankenhaus eines Gewebeschnitts mit einer Genauigkeit von 88% bis 98% identifizieren können. In einigen Fällen war die interne „Landkarte“ der Daten eines Modells primär nach Krankenhäusern organisiert und erst sekundär danach, ob das Gewebe gesund oder krebsartig war.
Dieser Effekt gelangte bereits Anfang des 20. Jahrhunderts zu einiger Berühmtheit, als ein Pferd – der „Kluge Hans“ – die Welt durch seine angeblichen Zähl- und Rechenfähigkeiten in Erstaunen versetzte. Allein: das Pferd konnte mit den Zahlen in Wirklichkeit nichts anfangen, sondern las das richtige Ergebnis an Mimik und Körpersprache seines Trainers ab.
Bildquelle: Kömen J, De Jong ED, Hense J et al., Nature Communications 2026 (CC BY-NC-ND 4.0)
Die Folgen können gravierend sein. In einem besonders eindrucksvollen Beispiel lernte ein KI-Modell, die Krankenhaus-Signatur als Abkürzung für seine Entscheidungen zu nutzen. Dadurch klassifizierte es einen eindeutig bösartigen Gewebeausschnitt fälschlicherweise als gesund – allein deshalb, weil die Probe aus einem Krankenhaus stammte, das in der Vergangenheit fast nur gesunde Proben geschickt hatte und das das Modell daher mit gesundem Gewebe assoziiert hatte.
Um dieses Problem messbar zu machen, entwickelten die Forschenden PathoROB, den ersten öffentlich verfügbaren Bewertungsmaßstab, der speziell die Robustheit von Foundation Models in der Pathologie gegenüber technischen Variationen adressiert. Er vereint vier Datensätze mit rund 100.000 Gewebeausschnitten, 28 biologischen Klassen und 34 medizinischen Zentren. Darüber hinaus führt er einen neuen „Robustheitsindex“ ein, der quantifiziert, wie stark die interne Repräsentation eines Modells von der Biologie und nicht von Krankenhausartefakten bestimmt wird.
Bei der Anwendung auf 20 weit verbreitete Foundation Models deckte PathoROB bei jedem einzelnen Modell Defizite auf. Größere Modelle, die auf vielfältigeren Daten trainiert wurden, sowie Modelle, die Bilddaten mit Textberichten kombinieren (Vision-Language-Modelle), erzielten die besten Ergebnisse. Die Forschenden testeten außerdem verschiedene nachträgliche Verfahren zur „Robustifizierung“ und stellten fest, dass diese das Risiko solcher Fehler deutlich reduzieren können – wenn auch noch nicht vollständig. Dabei ist kein kostspieliges erneutes Training des zugrunde liegenden Modells erforderlich.
„Foundation Models für die Pathologie entwickeln sich rasant, und das ist äußerst spannend. Unsere Ergebnisse zeigen jedoch, dass eine starke Leistung auf einem Standard-Benchmark nicht ausreicht, um einem Modell im klinischen Einsatz zu vertrauen“, sagt Julius Hense, Co-Erstautor der Studie und Forscher bei BIFOLD und der TU Berlin. „PathoROB gibt Entwicklerinnen, Entwicklern sowie klinischen Anwenderinnen und Anwendern ein Werkzeug an die Hand, um zu überprüfen, ob ein Modell tatsächlich biologische Zusammenhänge gelernt hat oder lediglich erkannt hat, aus welchem Krankenhaus ein Präparat stammt.“
PathoROB verändert schon heute die Art und Weise, wie KI für die Pathologie entwickelt und verglichen wird. Das gemeinsam mit der Mayo Clinic in den USA entwickelte Foundation Model der nächsten Generation von Aignostics, „Atlas 2“, wurde ausdrücklich darauf ausgelegt, die von PathoROB aufgedeckten Zielkonflikte zwischen Leistung und Robustheit zu adressieren. Darüber hinaus etabliert sich PathoROB zunehmend als Standardmaßstab für die Robustheit von Foundation Models. Neue Modelle oder auch Plattformen wie „Histoboard“ weisen ihre PathoROB-Ergebnisse inzwischen als einen der Bewertungsmaßstäbe auf, um Pathologie-KI-Modelle direkt miteinander zu vergleichen.
Durch die offene Bereitstellung des Bewertungsmaßstabs, der Datensätze und des Quellcodes hoffen die Forschenden, die Bewertung der Robustheit als festen Bestandteil der Validierung biomedizinischer Foundation Models zu etablieren – bevor diese zur Unterstützung klinischer Entscheidungen und damit potenziell zur Beeinflussung von Patientenbehandlungen eingesetzt werden.
Quelle: Technische Universität Berlin
29.06.2026