

News • Systematischer Prüfkatalog
Medizinische KI: Trainingsdaten auf dem Prüfstand
Künstliche Intelligenz (KI) in der Medizin kann helfen, Krankheiten früher zu erkennen, Menschen besser zu versorgen und die Gesundheitsausgaben zu senken.
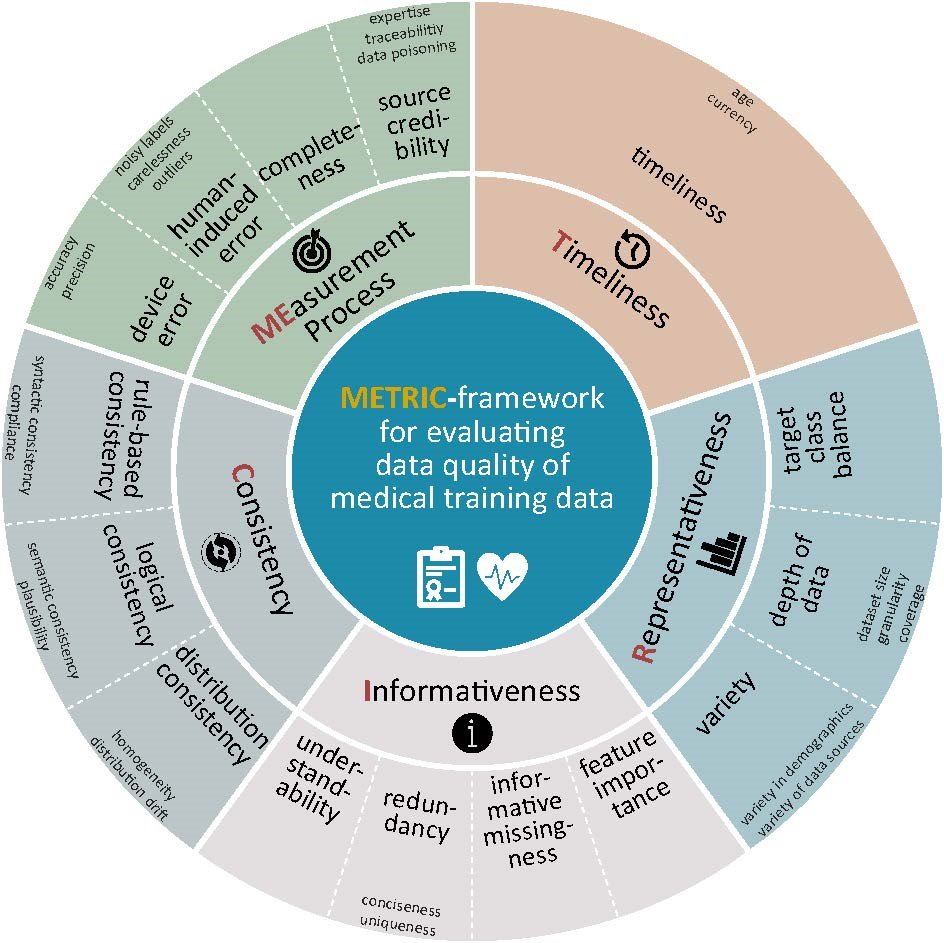
Bildquelle: PTB, von: Schwabe D et al., npj Digital Medicine 2024 (CC BY 4.0)
Die breite Verwendung hängt aber stark davon ab, ob Vertrauen in die Algorithmen aufgebaut werden kann. Eine entscheidende Frage lautet: Sind die Algorithmen mithilfe qualitativ hochwertiger Daten trainiert worden? In der Physikalisch-Technischen Bundesanstalt (PTB) ist ein neuer Prüfrahmen für solche Daten zur Entwicklung von KI-Medizinprodukten erstellt worden. Er bildet auch die Basis für einen agilen Zulassungsprozess solcher Softwareprodukte. Das Projektteam stellt dieses sogenannte METRIC-Framework in der Fachzeitschrift npj Digital Medicine vor.
KI bietet ein hohes Potenzial: So können die Algorithmen beispielsweise helfen, schnelle MRT-Aufnahmen des bewegten Herzens gestochen scharf zu machen. Oder sie können die Diagnosearbeit drastisch beschleunigen, indem sie große Mengen etwa von Vitaldaten (z. B. EKG), Laborwerten (z. B. Blutbild) und medizinischen Bildern schneller auswerten, als ein Mensch das kann. „Die Einsatzmöglichkeiten sind vielfältig und faszinierend. Aber alles steht und fällt damit, ob es gelingt, bei Ärzten und Patienten großes Vertrauen in die Sicherheit dieser Verfahren aufzubauen“, sagt Daniel Schwabe, Mathematiker bei der PTB. Hier setzte das Teilprojekt im Rahmen des europäischen TEF-Health-Projektes an, das Schwabe seit Anfang 2023 koordiniert und dessen erstes Ergebnis er jetzt mit seinem Team vorstellt.
Dies leistet einen großen Beitrag zum Ziel der Vertrauenswürdigkeit von KI-Medizinprodukten, wie es vom neuen EU-Gesetz (EU AI Act) gefordert wird
Daniel Schwabe
KI-Algorithmen müssen trainiert werden, indem ihnen beispielsweise Hunderte und Tausende medizinischer Daten zusammen mit der entsprechenden Diagnose vorgelegt werden. Daraus lernen sie, welche Daten und welche Diagnose zusammenpassen, und können schließlich selber Diagnosen stellen. „Es ist allgemein klar, dass die Qualität der Trainingsdaten ein entscheidender Punkt ist. Aber was steckt eigentlich genau hinter dem Begriff „Datenqualität“ im Kontext medizinischer Anwendungen? Das hat unser Team sich sehr gründlich angesehen“, erklärt Schwabe. Während einer akribischen Recherche, in die insgesamt 5408 Publikationen eingeflossen sind, haben die Forschenden den Begriff in einzelne Eigenschaften aufgespalten. Diese Systematik haben sie in einer Grafik aufgearbeitet, die sie das „Rad der Datenqualität“ nennen. Es legt den Grundstein für die systematische Analyse der Qualität medizinischer Trainingsdaten. Dies dient vor allem Entwicklern von KI-Medizinprodukten, um die Nutzbarkeit und Eignung ihrer Datensätze besser einzuschätzen. Wenn sie mehr über die Trainingsdaten wissen, verringert sich die Gefahr von Fehleinschätzungen. Das Endprodukt, also der KI-Algorithmus, wird robuster und besser interpretierbar. „Dies leistet einen großen Beitrag zum Ziel der Vertrauenswürdigkeit von KI-Medizinprodukten, wie es vom neuen EU-Gesetz (EU AI Act) gefordert wird “, sagt Schwabe.
Das Rad der Datenqualität kann auch zum Testen von KI-Algorithmen durch Verwendung von Referenzdatensätzen genutzt werden. Das wird die PTB auch in ihrem eigenen Projekt TraCIM nutzen, das im Frühjahr als Demonstrator auf der Hannover Messe vorgestellt wurde. Damit kann sie KI-Algorithmen für die Medizin bewerten. In Zukunft soll TraCIM es Herstellerfirmen ermöglichen, ihre KI-Algorithmen von der PTB als neutraler Stelle überprüfen zu lassen.
Als nächsten Schritt befasst sich das Projektteam um Daniel Schwabe mit der Frage, wie sich die gefundenen Eigenschaften der Datenqualität automatisiert messen lassen. Außerdem untersucht das Projektteam wie stark der Einfluss von einzelnen Faktoren der Datenqualität auf die Eigenschaften (z. B. Vorhersage-Qualität, Robustheit, Unsicherheit) eines KI-Medizinprodukts ist.
Quelle: Physikalisch-Technische Bundesanstalt
05.08.2024


