© Andreas Heddergott / TU München
News • Auswertung von Röntgenbildern
Eine klinische KI, die die Privatsphäre wahrt
Künstliche Intelligenz (KI) kann medizinisches Personal in der Diagnostik unterstützen. Sie zu trainieren erfordert allerdings den Zugriff auf ein schützenswertes Gut: medizinische Daten. Ein Forschungsteam der Technischen Universität München (TUM) hat eine Technik entwickelt, die die Privatsphäre der Patienten beim Trainieren der Algorithmen schützt.
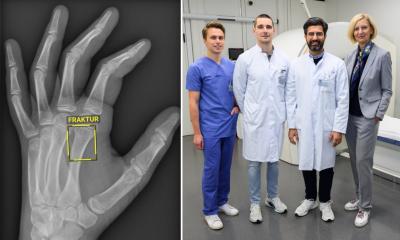
Anwendung findet die Technik nun erstmals in einem Algorithmus, der in Röntgenbildern Pneumonien erkennt.
Die digitale Medizin eröffnet heute bisher nicht dagewesene Möglichkeiten. Sie kann beispielsweise frühe Hinweise auf Tumore zu geben. Wie gut neue KI-Algorithmen sind, hängt allerdings von der Menge und der Qualität der Daten ab, an denen sie lernen.

© Andreas Heddergott / TU München
Um Algorithmen an möglichst vielen Daten zu trainieren, ist es gängige Praxis, persönliche Daten von Patienten zwischen Kliniken auszutauschen indem eine Kopie der Daten an die Kliniken gesendet wird, in denen der Algorithmus trainiert wird. Zum Datenschutz werden dabei zumeist die Verfahren der Anonymisierung und Pseudonymisierung angewendet – ein Vorgehen, das auch in der Kritik steht. „Es hat sich in der Vergangenheit mehrfach gezeigt, dass diese Vorgehensweisen keinen ausreichenden Schutz für die Gesundheitsdaten von Patientinnen und Patienten bieten“, sagt Daniel Rückert, Alexander-von-Humboldt-Professor für Artificial Intelligence in Healthcare and Medicine an der TUM.

© Astrid Eckert, München
Aus diesem Grund hat ein interdisziplinäres Team der TUM gemeinsam mit Forschenden des Imperial College London und der Non-Profit-Organisation OpenMined eine bislang einzigartige Kombination an Privatsphäre-wahrenden Verfahren für die KI-gestützte Diagnostik an radiologischen Bilddaten entwickelt. In der Fachzeitschrift Nature Machine Intelligence stellte das Team nun die erfolgreiche Anwendung vor: Ein Deep-Learning-Algorithmus, mithilfe dessen sich Pneumonien in Röntgenbildern von Kindern klassifizieren lassen. „Wir haben unsere Modelle gegen spezialisierte Radiologen getestet. Sie wiesen zum Teil eine vergleichbare oder höhere Genauigkeit in der Diagnose verschiedener Arten von Lungenentzündungen bei Kindern auf“, sagt Prof. Marcus R. Makowski, Direktor des Instituts für Radiologie am Klinikum rechts der Isar der TUM.

© Andreas Heddergott / TU München
„Damit die Daten der Patientinnen und Patienten sicher sind, sollten sie die jeweilige Klinik nie verlassen“, sagt Projektleiter und Erstautor Georgios Kaissis vom Institute for AI and Informatics in Medicine der TUM. „Wir haben für unseren Algorithmus das sogenannte Federated Learning verwendet, bei dem nicht die Daten geteilt werden, sondern der Deep-Learning Algorithmus. Unsere Modelle wurden in der jeweiligen Klinik mit den Daten vor Ort trainiert und danach wieder zu uns zurückgesendet. Die Besitzer mussten ihre Daten also nicht herausgeben und haben die komplette Kontrolle darüber behalten“, erklärt Erstautor Alexander Ziller, Forscher am Institut für Radiologie.
Damit sich keine Rückschlüsse auf die Daten einer bestimmten Institution ziehen lassen, mit denen der Algorithmus trainiert wurde, wandte das Team eine weitere Technik an: Die sichere Aggregierung. „Wir haben die Algorithmen verschlüsselt zusammengeführt und erst entschlüsselt, nachdem sie mit den Daten aller beteiligten Institutionen trainiert waren“, erklärt Kaissis. Damit keine Informationen über einzelne Patienten aus den Datensätzen herausgefiltert werden können – also die sogenannte Differential Privacy gewahrt ist – wandten die Forscher zusätzlich eine dritte Technik auf das Training des Algorithmus an. „Schlussendlich können zwar statistische Zusammenhänge aus den Datensätzen herausgelesen werden, nicht aber die Beiträge einzelner Personen zum Datensatz“, sagt Kaissis.

© Andreas Heddergott / TU München
„Die Methoden, die wir genutzt haben, sind zwar in früheren Studien schon zum Einsatz gekommen“, sagt Daniel Rückert, „bislang fehlten aber größere Studien an echten klinischen Daten. Durch die gezielte technische Weiterentwicklung und die Zusammenarbeit zwischen Spezialisten aus Informatik und Radiologie haben wir es geschafft, Modelle zu trainieren, die genaue Ergebnisse liefern und gleichzeitig hohe Anforderungen an Datenschutz und Privatsphäre erfüllen.“
Rickmer Braren, stellvertretender Direktor des Instituts für Radiologie, ergänzt: „Oft wird behauptet, dass Datenschutz und Datennutzung im Widerspruch zueinander stehen. Wir zeigen jetzt: Das muss nicht sein.“ Die Methode lasse sich auch auf andere medizinische Bilddaten als Röntgenbilder anwenden, sagen die Wissenschaftler. Zum Beispiel auf Sprach- und Textdaten.
Die Kombination der neuartigen Datenschutz-Verfahren erleichtert auch die Zusammenarbeit zwischen Institutionen, wie das Team in einer bereits 2020 in Nature Machine Intelligence erschienenen Publikation zeigte. Denn mit der Privatsphäre-wahrenden KI können ethische, rechtliche und politische Hürden genommen werden – somit könne man die KI breit anwenden und das sei enorm wichtig für die Erforschung seltener Erkrankungen, sagt Braren.
Die Wissenschaftler sind überzeugt, dass ihre Technik zur Wahrung der Privatsphäre einen wichtigen Beitrag für den Fortschritt der digitalen Medizin leisten kann. „Um gute KI-Algorithmen trainieren zu können, brauchen wir gute Daten“, sagt Kaissis. „Und diese erhalten wir nur, wenn wir die Privatsphäre der betroffenen Patientinnen und Patienten ausreichend schützen“, ergänzt Rückert. „Wir können mit Datenschutz also mehr zum Erkenntnisgewinn beitragen, als viele denken.“
Quelle: Technische Universität München
25.05.2021