News • „Swarm Learning“
KI mit Schwarm-Intelligenz analysiert medizinische Daten
Gemeinschaften profitieren vom Wissen und Erfahrungsaustausch ihrer Mitglieder. Nach einem ähnlichen Prinzip – „Swarm Learning“ genannt – hat ein internationales Forschungsteam Algorithmen der künstlichen Intelligenz darauf trainiert, in dezentral gelagerten Datenbeständen Blutkrebs, Lungenerkrankungen und Covid-19 zu erkennen.
Dieser Ansatz hat gegenüber herkömmlichen Verfahren den Vorteil, dass Anforderungen des Datenschutzes auf natürliche Weise erfüllt werden – was die standortübergreifende Analyse wissenschaftlicher Daten vereinfacht. Swarm Learning könnte daher die Zusammenarbeit und den Informationsaustausch in der Forschung, insbesondere im Bereich der Medizin, maßgeblich fördern und beschleunigen. Fachleute des Deutschen Zentrums für Neurodegenerative Erkrankungen (DZNE), der Universität Bonn, des IT-Unternehmens Hewlett Packard Enterprise (HPE) und weiterer Forschungseinrichtungen berichten darüber im Wissenschaftsjournal „Nature“.

Bildquelle: DZNE / Frommann
Wissenschaft und Medizin werden zunehmend digitaler. Die Analyse der dabei anfallenden Informationsmengen – „Big Data“ genannt – gilt als ein Schlüssel zu besseren Behandlungsoptionen. „Medizinische Forschungsdaten sind ein Schatz. Sie können entscheidend dazu beitragen, personalisierte Therapien zu entwickeln, die passgenauer als herkömmliche Behandlungen auf jeden Einzelnen zugeschnitten sind“, sagt Joachim Schultze, Direktor für Systemmedizin am DZNE und Professor am Life & Medical Sciences-Institut (LIMES) der Universität Bonn. „Für die Wissenschaft ist es wichtig, dass sie solche Daten so umfassend und von so vielen Quellen wie möglich nutzen kann.“
Allerdings unterliegt der Austausch medizinischer Forschungsdaten über Standorte oder gar Ländergrenzen hinweg den Anforderungen des Datenschutzes und der Datenhoheit. Diese Auflagen lassen sich in der Praxis meist nur mit erheblichem Aufwand umsetzen. Zudem gibt es technische Hürden: Etwa wenn gewaltige Datenmengen digital übermittelt werden sollen, können Datenleitungen schnell an Leistungsgrenzen stoßen. Angesichts dieser Bedingungen sind viele medizinische Studien lokal beschränkt und können Daten, die andernorts vorliegen, nicht verwerten.
Vor diesem Hintergrund erprobte ein Forschungsverbund um Joachim Schultze eine neuartige Vorgehensweise, um dezentral gelagerte Forschungsdaten auszuwerten. Grundlage dafür war die noch junge, von HPE entwickelte Technologie des „Swarm Learning“. Neben dem IT-Unternehmen beteiligten sich an dieser Studie zahlreiche Forschungseinrichtungen aus Griechenland, den Niederlanden und Deutschland – darunter Mitglieder der „German Covid-19 OMICS Initiative“ (DeCOI).
Dieser Artikel könnte Sie auch interessieren

News • "Gesichter" einer Krankheit
Covid-19: Forscher ermitteln mindestens 5 Varianten
Die vom Coronavirus SARS-CoV-2 verursachte Erkrankung Covid-19 umfasst nach aktuellen Untersuchungen mindestens fünf verschiedene Varianten. Diese unterscheiden sich darin, wie das Immunsystem auf die Infektion reagiert. Forschende des Deutschen Zentrums für Neurodegenerative Erkrankungen (DZNE) und der Universität Bonn präsentieren diese Befunde gemeinsam mit weiteren Fachleuten aus…
Swarm Learning kombiniert eine spezielle Form des Informationsaustausches über verschiedene Knoten eines Netzwerkes hinweg mit Methoden aus dem Werkzeugkasten des „maschinellen Lernens“, einem Teilbereich der künstlichen Intelligenz (KI). Dreh- und Angelpunkt des maschinellen Lernens sind Algorithmen, die an Daten trainiert werden, um darin Gesetzmäßigkeiten aufzuspüren – und infolgedessen die Fähigkeit erwerben, die gelernten Muster auch in anderen Daten zu erkennen. „Swarm Learning eröffnet der Medizinforschung, aber auch der Wirtschaft, neue Möglichkeiten der Zusammenarbeit. Der Schlüssel liegt darin, dass alle Kooperationspartner voneinander lernen können, ohne vertrauliche Daten teilen zu müssen“, sagt Dr. Eng Lim Goh, Senior Vice President und Chief Technology Officer für künstliche Intelligenz bei HPE. In der Tat: Beim Swarm Learning bleiben sämtliche Forschungsdaten vor Ort. Ausgetauscht werden nur Algorithmen und Parameter – gewissermaßen Erfahrungswerte. „Swarm Learning erfüllt die Vorgaben des Datenschutzes auf natürliche Weise“, betont Joachim Schultze.
Alle Mitglieder des Schwarms sind gleichberechtigt. Es gibt keine zentrale Macht über das Geschehen und die Ergebnisse, also gewissermaßen keine Spinne, die das Datennetz kontrolliert
Joachim Schultze
Anders als beim „Federated Learning“, bei dem die Daten ebenfalls lokal verbleiben, gibt es keine zentrale Kommandostelle, erläutert der Bonner Wissenschaftler. „Swarm Learning geschieht kooperativ anhand von Regeln, auf die sich alle Partner vorab verständigt haben. Dieses Regelwerk wird in einer Blockchain festgehalten.“ Hierbei handelt es sich um eine Art digitales Protokoll, das den Informationsaustausch zwischen den Parteien verbindlich regelt, sämtliche Ereignisse dokumentiert und das alle Beteiligten einsehen können. „Die Blockchain ist das Rückgrat des Swarm Learning“, so Schultze. „Alle Mitglieder des Schwarms sind gleichberechtigt. Es gibt keine zentrale Macht über das Geschehen und die Ergebnisse, also gewissermaßen keine Spinne, die das Datennetz kontrolliert.“
Die KI-Algorithmen lernen somit lokal, nämlich anhand der Daten, die am jeweiligen Netzwerkknoten vorliegen. Die Lernerfolge jedes Knotens werden in Form von Parametern über die Blockchain gesammelt und in intelligenter Weise vom System verarbeitet. Daraufhin optimierte Parameter werden an alle Beteiligte weitergegeben. Dieser Ablauf wiederholt sich mehrfach, wodurch sich die Fähigkeit der Algorithmen Muster zu erkennen nach und nach verbessert – und zwar an jedem Knoten des Netzwerkes.
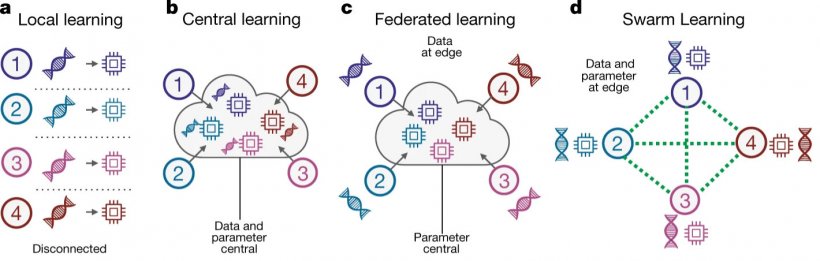
Bildquelle: Warnat-Herresthal et al., Nature 2021 (CC BY 4.0)
Den Praxisbeweis dafür liefern die Forschenden nun anhand der Analyse von Röntgenbildern der Lunge und sogenannter Transkriptome: Bei Letzteren handelt es sich um Daten zur Genaktivität von Zellen. In der aktuellen Studie ging es konkret um Immunzellen, die im Blut zirkulieren – also um weiße Blutkörperchen. „Daten der Genaktivität von Blutzellen sind wie ein molekularer Fingerabdruck. Sie enthalten wichtige Informationen darüber, wie der Organismus auf eine Erkrankung reagiert“, sagt Schultze. „Transkriptome liegen genauso wie Röntgenbilder in großer Menge vor und sie sind hochkomplex. Genau die richtige Art von Informationen für eine Analyse mit künstlicher Intelligenz. Solche Daten sind ideal, um Swarm Learning zu testen.“
Das Forschungsteam nahm sich insgesamt vier infektiöse und nicht-infektiöse Erkrankungen vor: zwei Varianten von Blutkrebs (Akute Myeloische Leukämie und Akute Lymphoblastische Leukämie), außerdem Tuberkulose und Covid-19. Die Daten umfassten insgesamt mehr als 16.000 Transkriptome. Das Swarm-Learning-Netzwerk, über das die Daten verteilt waren, bestand in der Regel aus mindestens drei und bis zu 32 Knoten. Unabhängig von den Transkriptomen analysierten die Forschenden rund 100.000 Röntgenbilder des Brustkorbs. Diese stammten von Patienten mit Flüssigkeitsansammlungen in der Lunge oder anderen pathologischen Befunden sowie von Personen ohne Auffälligkeiten. Diese Daten waren über drei verschiedene Knoten verteilt.
Die Analyse sowohl der Transkriptome wie auch der Röntgenbilder folgte dem gleichen Prinzip: Zunächst fütterten die Forschenden ihre Algorithmen mit Teilmengen des jeweiligen Datensatzes. Dazu gehörte auch die Information, welche der Proben von Patienten stammten und welche von Personen ohne Befund. Mit der so erlernten Mustererkennung für „krank“ beziehungsweise „gesund“ wurden dann weitere Daten klassifiziert – das heißt: eingeteilt in Proben mit oder ohne Erkrankung. Die Treffsicherheit, also die Fähigkeit der Algorithmen zwischen gesunden und erkrankten Personen zu unterscheiden, lag bei den Transkriptomen im Durchschnitt (jede der vier Erkrankungen wurde separat ausgewertet) bei rund 90 Prozent, im Falle der Röntgendaten reichte sie von 76 bis 86 Prozent.
Swarm Learning hat das Potential eines echten Gamechangers und könnte helfen, den Erfahrungsschatz der Medizin weltweit zugänglicher zu machen
Joachim Schultze
„Das Verfahren funktionierte am besten bei Leukämie. Hier ist die Signatur der Genaktivität besonders auffällig und somit für künstliche Intelligenz am einfachsten zu erkennen. Infektionserkrankungen sind variabler. Dennoch war die Treffsicherheit bei Tuberkulose und Covid-19 ebenfalls sehr hoch. Bei den Röntgendaten war die Quote etwas niedriger, was mit der geringeren Daten- beziehungsweise Bildqualität zusammenhängt“, kommentiert Schultze die Ergebnisse. „Unsere Studie belegt somit, dass sich Swarm Learning auf ganz unterschiedliche Daten erfolgreich anwenden lässt. Prinzipiell gilt das für jede Art von Information, bei der eine Mustererkennung anhand künstlicher Intelligenz sinnvoll ist. Seien es Genomdaten, Röntgenaufnahmen, Bilddaten aus dem Hirnscanner oder andere komplexe Daten.“ Die Studie ergab zudem, dass Swarm Learning deutlich bessere Ergebnisse lieferte, als wenn die Knoten des Netzwerkes unabhängig voneinander lernten. „Jeder Knoten profitiert von den Erfahrungswerten der anderen Knoten, obwohl immer nur lokale Daten zur Verfügung stehen. Das Konzept des Swarm Learning hat damit den Praxistest bestanden“, sagt Schultze.
„Ich bin davon überzeugt, dass Swarm Learning der medizinischen Forschung und anderen datengetriebenen Disziplinen einen enormen Schub geben kann. Die aktuelle Studie war nur ein Testlauf. Künftig wollen wir diese Technologie auf Alzheimer und andere neurodegenerative Erkrankungen anwenden“, so Schultze. „Swarm Learning hat das Potential eines echten Gamechangers und könnte helfen, den Erfahrungsschatz der Medizin weltweit zugänglicher zu machen. Nicht nur Forschungseinrichtungen, auch beispielsweise Krankenhäuser könnten sich zu solchen Schwärmen zusammenschließen und damit Informationen zum gegenseitigen Nutzen austauschen.“
Quelle: Deutsches Zentrum für Neurodegenerative Erkrankungen
27.05.2021