News • Auditory Attention Decoding
Hearing aid uses deep neural network to filter out the noise
Columbia Engineers make major advance in helping the hearing impaired follow a conversation in a noisy environment - and bring cognitive hearing aids a step closer to reality.
People who are hearing impaired have a difficult time following a conversation in a multi-speaker environment such as a noisy restaurant or a party. While current hearing aids can suppress background noise, they cannot help a user listen to a single conversation among many without knowing which speaker the user is attending to. A cognitive hearing aid that constantly monitors the brain activity of the subject to determine whether the subject is conversing with a specific speaker in the environment would be a dream come true.
Using deep neural network models, researchers at Columbia Engineering have made a breakthrough in auditory attention decoding (AAD) methods and are coming closer to making cognitively controlled hearing aids a reality. The study, led by Nima Mesgarani, associate professor of electrical engineering, is published in the Journal of Neural Engineering. The work was done in collaboration with Columbia University Medical Center’s Department of Neurosurgery and Hofstra-Northwell School of Medicine, and Feinstein Institute for Medical Research.
Our system demonstrates a significant improvement in both subjective and objective speech quality measures
Nima Mesgarani
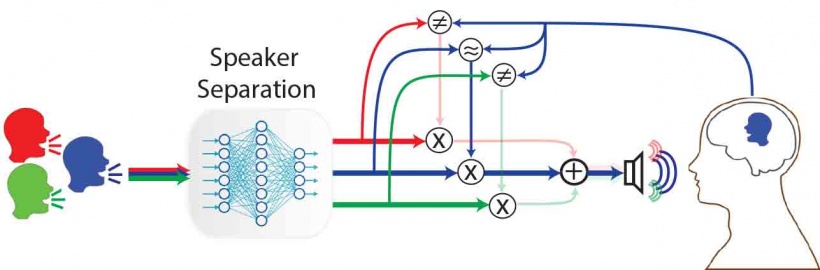
Mesgarani’s team developed an end-to-end system that receives a single audio channel containing a mixture of speakers by a listener along with the listener’s neural signals, automatically separates the individual speakers in the mixture, determines which speaker is being listened to, and then amplifies the attended speaker’s voice to assist the listener—all in under 10 seconds. “This work combines the state-of-the-art from two disciplines: speech engineering and auditory attention decoding,” says Mesgarani, who is also a member of the Data Science Institute and the Mortimer B. Zuckerman Mind Brain Behavior Institute. “We were able to develop this system once we made the breakthrough in using deep neural network models to separate speech.”
His team came up with the idea of a cognitively controlled hearing aid after they demonstrated it was possible to decode the attended target of a listener using neural responses in the listener’s brain using invasive neural recordings in humans (Nature 2012). Two years later, they showed they could decode attention with non-invasive methods as well (Cerebral Cortex 2015). “Translating these findings to real-world applications poses many challenges,” notes James O’Sullivan, a postdoctoral research scientist working with Mesgarani and lead author of the study. In a typical implementation of auditory attention decoding, researchers compare the neural responses recorded from a subject’s brain with the clean speech uttered by different speakers; the speaker who produces the maximum similarity with the neural data is determined to be the target and is subsequently amplified. However, in the real world, researchers have access only to the mixture, not the individual speakers. “Our study takes a significant step towards automatically separating an attended speaker from the mixture,” O’Sullivan continues. “To do so, we built deep neural network models that can automatically separate specific speakers from a mixture. We then compare each of these separated speakers with the neural signals to determine which voice the subject is listening to, and then amplify that specific voice for the listener.”
The team tested the efficacy of their system using invasive electrocorticography recordings from neurological subjects undergoing epilepsy surgery. They identified the regions of the auditory cortex that contribute to AAD and found that the system decoded the attention of the listener and amplified the voice he or she wanted to listen to, using only the mixed audio. “Our system demonstrates a significant improvement in both subjective and objective speech quality measures—almost all of our subjects said they wanted to continue to use it,” Mesgarani says. “Our novel framework for AAD bridges the gap between the most recent advancements in speech processing technologies and speech prosthesis research and moves us closer to the development of realistic hearing aid devices that can automatically and dynamically track a user’s direction of attention and amplify an attended speaker.”
Source: Columbia University School of Engineering and Applied Science
07.08.2017