

Sponsored • Lab IT
Old software makes old mistakes …
Since the microprocessor entered the medical laboratory we have watched how those responsible also have been confronted with the errors in the software supplied with it.

Obviously, such errors are to be avoided or found and corrected before use. Nonetheless complete error-free software remains a dream. ISO 15189:2012 makes it obligatory for the manufacturer to identify errors in the form of validation and for the user in the form of verification. ISO 9000:2015 defines an error as failure, incorrect behaviour or incorrect performance (the desired action is not performed) by a person. Origins of human errors are ignorance, incompetence or refusal. A human error leads to a (even unrecognised) defect that can cause a failure. For example, the program instruction “x = a/b”: ignoring the case of “b = 0” has the effect of a defective program and leads to a collapse of the system when b reaches the value 0.
Software development as complex process (Cynefin Framework)
Why is that? A good tool for phenomenological tracking of software errors is the Cynefin Framework. This is a knowledge management module used to describe problems, situations and systems. It delivers a typology of domains that offer an approach for which kind of explanations and/or solutions could be correct. The point is to expose in a clear manner the evolutionary structure of complex systems, including an inherent uncertainty. The Welsh word “Cynefin” – inadequately translated as habitat, haunt, acquainted, familiar– points to the fact that human interaction is heavily influenced by experiences (personal as well as collective), if not in fact defined by them.

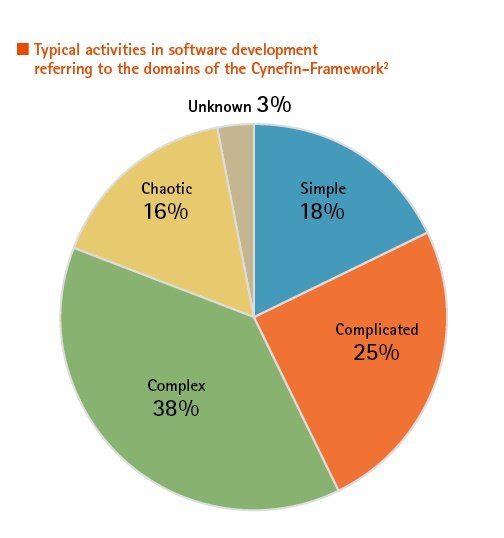
Image 1 shows the four domains (contexts) of the framework: these are distinguished by the different degree of perception of causality/coupling between cause and effect in the system under examination. Starting with “obvious” and a strict coupling, it changes anti-clockwise until there is a chaotic system where no cause and effect relationship is recognisable.
Depending on how a situation is classified in one of these domains, there are options for action available. Thus, for the medical laboratory analysis and diagnostics are usually characterised as complicated whereas medical research is considered complex. To understand error avoidance and identification in medical software the effect of one’s own perception of the respective context is decisive: by learning and training it is possible to arrive at a deeper understanding of causality in a specific context and thus to move in a clockwise sense within the domain. For the software manufacturer in the laboratory the opposite direction is also familiar: the depletion of knowledge by the loss of experienced employees has brought some enterprises on the brink of chaos recently.
Given that according to their own estimate, people employed in software development see more than 50 per cent of their time as spent with complex and chaotic scenario, the situation for a laboratory that is supposed to judge the quality of software used, seems rather hopeless. Fortunately, the Framework also offers indicators here: so best and good practices are not necessarily helpful; rather in this environment emergent and utterly new practices can be applied here. Also, the “chaotic” context is not to be understood as static—rather it opens the possibility for predicting reactions in the entire system by application of strict and formal rules to thus attain the “obvious” context.
Assistance for the user
The following procedures can be considered:
- Supplier audit: before entering a longer-term contractual relationship with a software supplier, there should at least be a check to see if this supplier really fits. It can be determined then whether the manufacturer is aware of the complexity of his assignment and how he has mastered this.
- Verification: In the context ranges complex and chaotic, emergent and novel practices ought to be applied. In other words, things ought to be “tested” or “just done”. The aim is to create conditions by means of program entries that will force a system failure and thus expose a defect in the program code. It has been shown that software products tend to reproduce certain error types due to the programming language, tools used, persons involved and last but not least intended functions. A detailed record and categorisation of errors found in the past is an aid not to be underestimated for the verification.
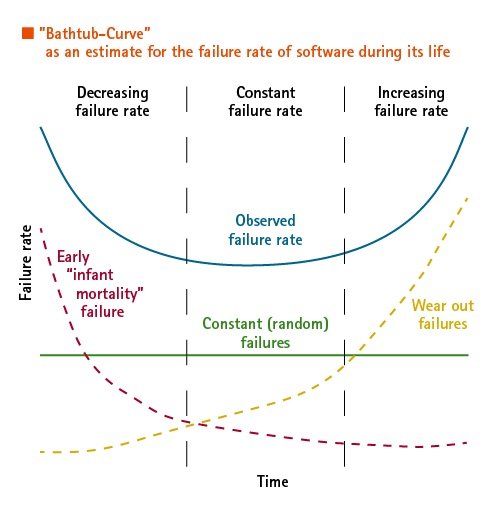
- Statistics: Another indicator of software stability is the quantitative analysis of the number of errors found during verification. As is the case with every engineering product there is also a similar course (bathtub curve) followed through the product lifetime and this enables the user to estimate the “software age” and thus predict whether the software used will soon reach a condition in which the number of errors renders further use inefficient.
Recommended article

Article • Lab shopping list
Marry (a LIS) in haste, repent at leisure
Buying a laboratory information system (LIS) means entering a long-term relationship with a software vendor. The selection criteria are many, but which, ask Markus Neumann, Harald Maier and Gabriele Egert, are just fashionable and which might be underestimated? The decision to buy a LIS – i.e. to form a relationship with one or more software vendors – is based on a slew of criteria, and…
Outlook for new software ... and new errors
New demands on software in laboratories are increasingly met by new technologies in operations and the development of this software. The therapy decision is oriented more and more toward the individual patient with his complex biological profile. Identification and assessment of the profile requires a steady growth in the processing capacity of IT systems. They also require application of new paradigms and algorithms for pattern recognition and machine learning — often known collectively by the term “artificial intelligence”.
The new software and hardware paradigms lead to a new type of complexity and thus to new errors. “People” create in machine learning only the foundation for learning. Learning itself is determined by the machine’s “learning environment” and its training data sets, the quality of which again influence the system’s capability of distinguishing between the healthy and ill. An error in this categorisation can originate at any level of the overall system — in extreme cases; the system has learned the wrong selector. Hence the task of validation, as before, is to measure the impact of this “defect” to derive the necessary actions (to eliminate the error).
Also, the definition of errors in the field of AI algorithms leads to sharpening of the concept of human responsibility: as stated by the norm, errors are always due to human acts, since AI cannot make any mistakes on its own. If it acts unpredictably for human reasoning, this creates an incomparably greater ethical responsibility for the construction of IT systems, training and particularly the training data. If health professionals are to authorize the use of AI on a patient, every referring activity must be recorded in detail to show at any time to patients, inspection authorities and the public that due diligence has been exercised.
Profile:
After having obtained a degree in analytical chemistry, Dr Markus Neumann has had different roles in software development for laboratory information systems. After founding the company Labcore together with Heiko Kindler in 2006, the software specialist has also been focusing on quality management and process optimisation in medical laboratories.
04.08.2019


